1 建设概况
新型冠状肺炎病毒突发,不但给国家公共卫生治理体系和治理能力带来了一次大考,也引起了各界广泛关注。当前,全球范围内疫情仍呈扩散蔓延趋势,Delta株等变异病毒株不断出现,病毒传播力有所增强。我国局部地区先后发生本土聚集疫情,外防输入、内防反弹压力持续存在,疫情防控形势依然严峻。其中办公园区人员流量大,人员活动密集,如疫情入园后将难以控制。疫情期间公司总部大厦人流量大、人群密集、疫情防控压力大,需持续抓好常态化疫情防控不放松。为响应国家号召,按照“不带风险来,不让风险走”的目标,本次建设意在以公司顶层设计为指引,以构建“智慧后勤”为目标,在试点单位实施的基础上,开展智慧后勤建设项目。帮助试点单位实现公共卫生的全区域、全角色、全层级、全方位管控,全面打造高安全低风险的智慧化园区,实现公司层面整体管控的目标。
2 建设内容
根据建设目标,将公共卫生防护系统整体建设内容分为四个部分:
1.“控”出入口:区域建设、人员通行、车辆通行、环境监测、基础平台。主要实现驻厦人员、访客和车辆人员的健康通行管理。提供环境监测作为辅助决策。
2.“重”监测:人员行为监测、访客一体化管理、内部环境监测。
3.“断”传播:重点区域消杀、医务室购药人员健康监测。
4.“统“指挥:建设统一的总控平台,配合APP手机端、微信小程序等移动化手段,实现防控中心、事件处理以及应急告警等功能。完成对人员健康的全面管控。
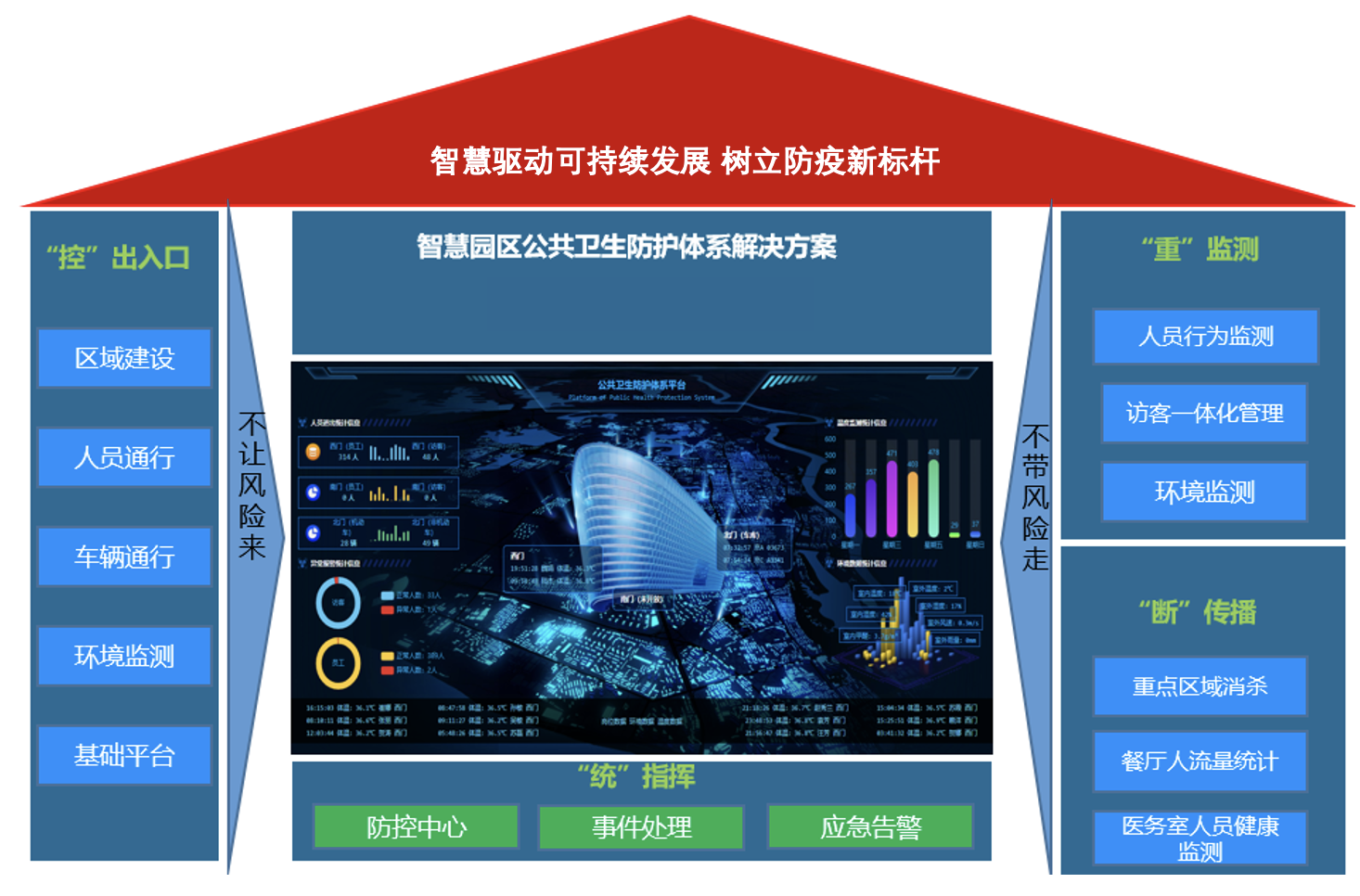
图 1公共卫生防护系统架构图
建设的公共卫生防护系统出入口健康管理模块,主要完成“控”出入口部分的建设。本次项目集团从项目整体规划出发,对公共卫生防护整体把控。对“重”监测、“断”传播、“统“指挥内容进行建设招标。建设内容包含并不限于:
公共卫生防护系统应提供整体信息化层面的平台、应用及硬件支撑,并需对接现有智能化系统,系统主要建设包括:
Ø 一套园区公共卫生防护平台
1.公共卫生防护可视化模块(“统”指挥)
2.公共卫生防护服务管理模块及移动端微信小程序模块(“重”监测、“断”传播);
Ø 一套园区物联网支撑平台;
Ø 一套相关智能化基础设施;
Ø 一套符合实际管理需要的信息化支撑体系;
3 公共卫生整体方案设计
规划数据平台的设计理念是以区域性智能数据中心和高速互联网为基础设施,以互联网服务体系为架构,以大规模海量数据存储、处理、挖掘和可视化分析等关键技术为支撑,通过多样化智能终端及互联网为用户提供数据存储、管理及分析服务。
数据平台部署于智慧云平台上,建立面向公共卫生互联网对象的物理模型、资产模型、计算模型、三维模型及地理位置模型等多维模型,建立面向公共卫生互联网对象值属性的实时态、历史态、规划态等多态数据中心,最终实现一体化模型与数据管理和海量信息统一存储与访问,为多维度、多时空的数据高级展示、智能分析和应用二次开发提供坚实的数据访问和功能调用服务。在此基础上实现公共卫生网络的监视、分析、控制和辅助决策的一体化可视展现,大数据平台的技术架构如下图所示:

图 2技术架构
基础设施层:支持平台运行的网络环境、软件环境及硬件资源。主要包括网络、主机、存储、软件平台等。
数据资源层:由数据源和数据接入构成,数据源主要包括关系数据库、实时数据库、非关系型数据库等,其中事务数据及统计数据选用关系数据库,海量日志选用非关系型数据库,实时数据选用实时数据库。数据接入的方式有JDBC适配器、ETL、数据复制、Web Service等。数据源指定了平台数据的访问和存储方式。
业务层:用于部署业务逻辑组件,包含应用支撑技术组件,服务引擎、协议转换、规则引擎、数据核查、权限服务、服务监控、日志服务、缓存服务、任务调度、采集服务等。主要采用Java Bean或EJB技术加以实现,其中规则库和规则引擎基于drools进行二次开发加以实现,统计报表采用集成润乾等商业报表产品的方式,缓存服务建议采用独立部署的缓存服务器。
服务层:基于服务总线的技术架构,实现同步查询服务、异步查询服务、订阅服务、服务代理、消息服务等。
展现层:在J2EE技术体系中,可采用MVC应用框架,由界面控制器组件、界面操作组件JSP页面组件和服务代理单元组成。在一些特殊业务处理时,采用Flex、Java Swing、android sdk、html等技术实现。
采用所见即所得的交互式图表技术
所见即所得的交互式图表技术拥有响应式WEB设计,Dashboard交互式关键界面,实现数据多维分析,提供各种数据挖掘和数据预警功能,提供各种样式的表格和图表展示服务。其中图表展示包括列表、分组、交叉表格、柱形图、条形图、饼图、面积图、仪表盘和地图等。界面设计根据设备环境以及用户行为进行响应和调整,满足用户对于PC、平板及手机不同设备的使用需求。允许用户基于Dashboard组件定制自己的用户界面。
4 公共卫生应用层方案设计
要以目前运营管理的实际需求为依据,分阶段逐步实现园区的智慧化建设;尤其是公共卫生防护安全和通行作为园区基本功能,并且需结合公司大厦公共卫生防护系统现有建设内容,特别是实现重要区域卫生防护系统覆盖,利用人脸、行为等识别技术,帮助管理人员快速确认异常行为人员的真实身份或类别,同时对特殊人员行为进行实时识别预警,提供数据支撑,优化安保流程。同时具备通知发布模块、会议室/重点区域环境消杀模块、医务室购药人员健康管理等相关模块,对各大厦进行全方位公共卫生管理。
5 公共卫生防护平台数据处理层方案设计
5.1 总体方案
5.1.1 软件架构
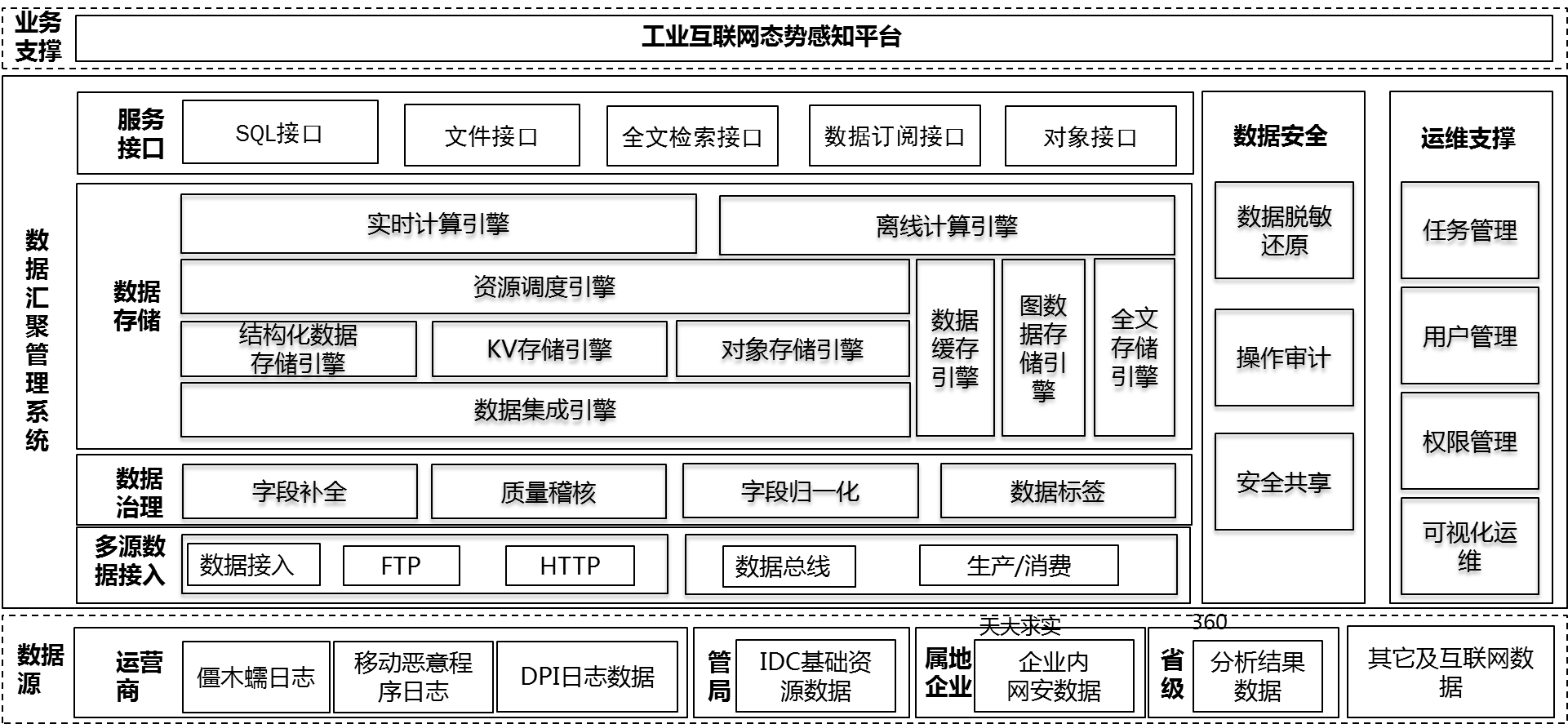
图 1软件架构
上图所示为本次投标方案数据汇聚管理系统的软件架构,主要包括数据汇聚、数据分析、数据存储、服务接口、数据安全、运维支撑共6个模块;
数据汇聚:数据汇聚模块提供ftp和http两种数据接入接口,支持将公司总部大厦、公司分部大厦的数据汇聚到数据总线,提供数据总线以支持对汇聚数据的缓存;
数据分析:数据分析模块提供对汇聚的数据的字段补全、质量稽核、字段归一化、数据标签等操作,实现数据质量提升;
数据存储:数据存储提供数据集成引擎、结构化数据存储、KV数据存储引擎、对象数据存储引擎、图数据存储引擎、全文数据存储引擎,提供统一的资源调度机制,提供实时和离线计算框架,为数据治理、数据预处理等操作提供资源和计算框架支持;
服务接口:支持对存储在数据存储引擎和数据总线上的数据对外提供SQL接口、文件接口、全文检索接口、数据订阅接口和对象接口;
数据安全:数据安全模块提供数据全流程的安全机制,具体包括敏感数据的数据脱敏、加扰、加密、还原等功能,以及对数据操作的全流程审计功能和数据安全共享功能;
运维支撑:提供可视化方式实现系统的任务管理、用户管理、权限管理和可视化监控;
5.2 数据汇聚
数据汇聚模块是将来自总公司大厦、公司分部大厦数据,采用多种数据接入方式将数据接入至数据总线,经过实时预处理后将数据持久化至数据存储平台,为上层工业互联网态势感知平台业务提供数据。
5.2.1 数据接入
数据接入主要提供结构化数据接入、非结构化数据接入、半结构化数据接入、加载容灾、并行接入、数据整理、数据校验的能力。支持的接入方式包括但不限于HTTP汇聚、FTP汇聚方式。
该模块主要实现了对日志数据、资产数据、安全事件数据等数据的高效加载功能。并在加载过程中实现了数据加载容灾、负载均衡以及数据可靠性和合法性的验证。系统由非结构化加载服务、结构化/半结构化数据加载服务、持久化服务组成。其中,非结构化加载服务的前端使用LVS进行负载均衡、加载容错,后端通过HTTP Server实现故障检测、用户认证、数据解析、数据校验等功能;结构化和半结构化数据加载也是采用LVS实现负载均衡和容错,后端通过FTP、HTTP接口支持用户数据加载、数据合并、校验等功能;数据持久化支持分布式部署,支持对所有结构化、非结构化数据的持久化功能,支持将数据按照配置持久化到Hive、全文或HBase中,并按照业务的配置进行自动分区计算,分区支持hash、等值、范围等多种方式。
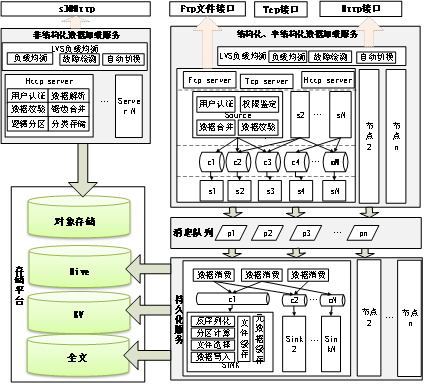
图 2异构数据高效加载设计示意图
主要的关键技术说明如下:
设计加强了数据合法性校验,可支持所有加载数据类型的合法性校验。既包括发送数据的字段数是否一致,也包括数据内容与声明的格式是否一致。支持CSV、AVRO两种数据格式的校验。支持灵活配置的校验级别,可自定义校验规则。校验内容包括字段数目,字符长度、字段类型、取值范围等。校验在数据进入数据总线前完成,校验不合法有明确的提示。
设计加强了非结构化数据的加载能力。非结构化数据加载支持分片、不分片两种上传方式。不分片方式支持的单个文件达到2GB。分片上传下载支持多线程的方式,优化传输策略提高传输效率。支持返回链接下载,用户直接使用链接下载文件,不需要中间缓存。支持基于文件桶的权限控制,可以对特定用户进行访问权限控制,权限包括上传、下载等。增强校验,能够对传输文件的正确性进行校验。提供非结构化数据的上传、下载的开发包,支持大文件上传的切割和下载的合并,文件上传下载的断点续传。支持Java,C/C++,Python等开发语言。
采用HiveMetastore进行统一元数据描述,目前已经实现了对Hive、全文表的复杂类型支持。
采用Flume并发框架进行数据收集和分发,支持对Hive、ES、HBase等多种引擎的持久化能力,实现了分区自动计算,并加入了文件句柄控制等模块,充分考虑了短时间内超多分区数据进入的情况,并在实践中得到验证,该功能已经在线使用,单机Hive表持久化速度可达300MB/S。
此外还对Kafka Rebanlance过程以及生产和消费能力进行了优化,单台服务器生产和消费性能到达1.4GB/s及以上。
5.2.2 数据总线
数据总线将各类日志数据、事件数据、资产数据统一汇聚至数据总线。同时,提供分区控制、数据订阅、消费特性控制、数据生产、数据复杂订阅、数据镜像、数据副本的能力,按照给定的订阅语法,实现数据定向推送功能。
数据总线是一种分布式的、支持分区的、多副本的,基于发布/订阅的消息系统。为了应对海量数据的接入和缓存,以及数据的高效共享和传输,采用松耦合技术架构设计,通过隐含的、基于数据的接口层,将消息发布端和消息订阅端解耦。提供消息持久化功能,当达到配置的消息数量或时间长度上限条件时,将消息持久化到磁盘,保证消息的可靠性和可回溯性。消息传输和共享即支持消息队列模式,也支持发布订阅模式,适应了不同场景的需求。
数据总线的总体实现逻辑如下图所示:
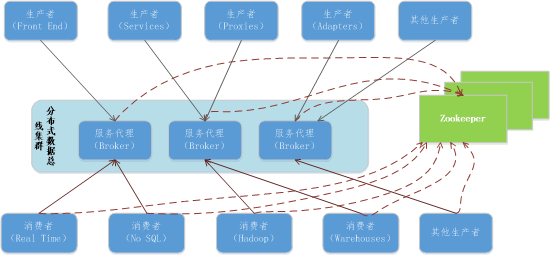
图 3数据总线总体实现逻辑图
数据总线采用集群化部署模式,每台服务器上部署个到多个服务代理,承载不同主题的分区,实现分布式并行消息服务,采用Zookeeper进行统一协调。
在生产端,提供对各种类型消息生产者的支持,生产者采用推送的机制,将消息发布到服务代理的主题中,生产者类型包括但不限于以下类型:
Ø 前端Web应用程序产生的应用日志
Ø 代理产生的Web分析日志
Ø 适配器产生的转换日志
Ø 服务产生的调用跟踪日志
在消息端,提供对各种类型消息者的支持,消息者采用拉取的机制,将消息从服务代理的主题中订阅到本地,进行各种数据处理操作,消费者类型包括但不限于以下类型:
Ø 离线消费者,如Hadoop或者传统数据仓库,消费消息并存储到本地,进行离线分析
Ø 近实时消费者,如HBase或者Cassandra等NoSQL数据库,消费消息并存储到本地,进行近实时分析
Ø 实时消费者,如Storm或者分布式内存计算任务,在内存中进行消息过滤,并实时触发事件报警
数据总线信息流程如下图所示:
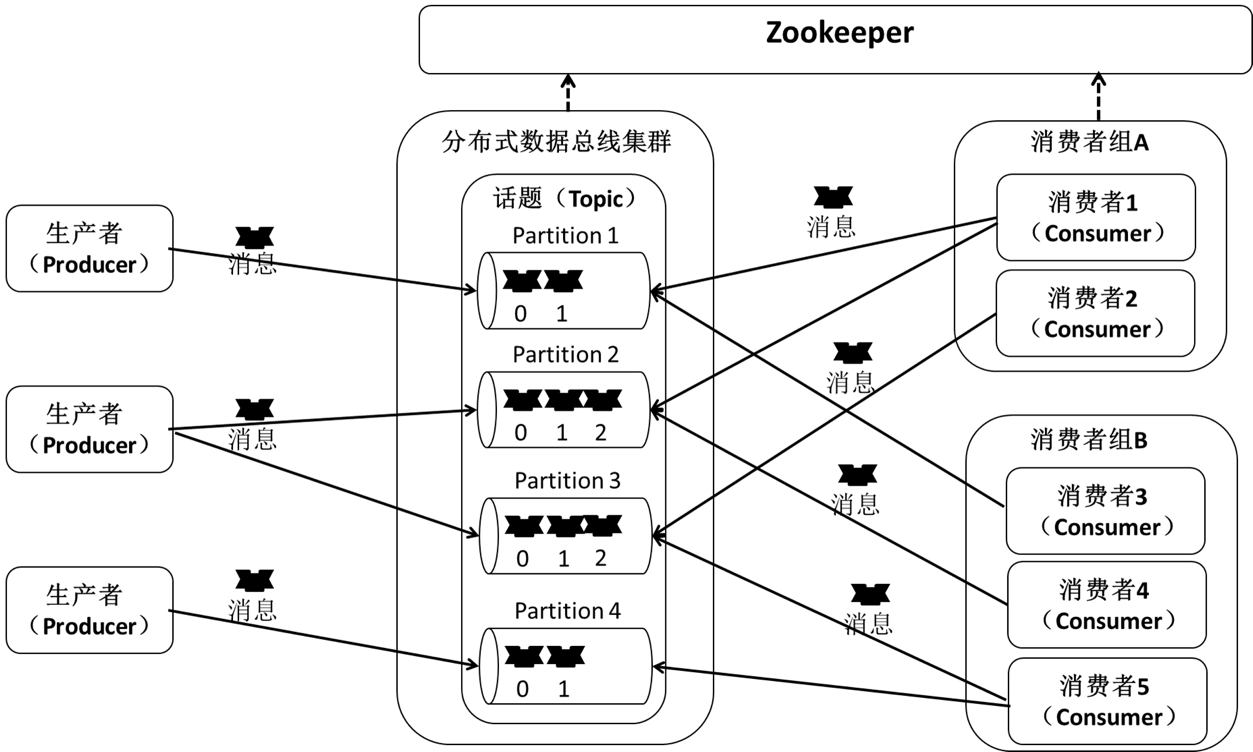
图 4数据总线信息流程图
数据总线的基本信息流程实现,由生产者推送消息到不同主题的不同分区中,实现消息的发布;在分布式数据总线集群中,不同的服务器节点可以运行一到多个服务代理,每个服务代理可以创建一到多个主题,每个主题可以划分一到多个分区,同一主题的不同分区可跨服务器节点分片管理和存储;消费者可以订阅一到多个主题,拉取消息进行数据处理操作,不同的消费者组成消费者组,同一个主题分区只能被同一个消费者组内的一个消费者订阅。服务代理和消费者采用Zookeeper获取分布式数据总线对象的状态信息,以及跟踪消费消息的偏移量。
数据总线的主题可以划分为一到多个分区,每个分区对应一个存储文件夹,包含大小相等的多个分段数据文件,用于存储该分区的所有消息。每个分区由一系列有序的、不可变的消息队列构成,每条消息按顺序分配一个唯一的序列号,用于唯一标识分区内的每条消息。当新消息被推送到分区时,服务代理将该消息追加到相应文件夹下最后一个分段数据文件末。当满足指定的消息数量或指定时长时,分段数据文件被固化到磁盘,此时消息能够被消费者订阅消费。
在数据总线中,服务代理是无状态的,其并不记录哪些消息被哪些消费者消费过,而是由消费者维护已消费消息的状态信息。
5.2.3 数据实时预处理
将日志数据、事件数据、资产数据等多源数据,汇总到数据总线,对所接入相关数据进行数据内容核验、格式转换、数据清洗等预处理操作。数据实时预处理模块主要分为数据校验、数据拆分、数据过滤、数据去重等操作,实现对不同运营商重复数据的筛选。
(1)数据校验
在数据加载构成中,加强了数据校验功能,可支持所有加载数据类型的合法性校验。既包括发送数据的字段数是否一致,也包括数据内容与声明的格式是否一致。支持CSV、AVRO两种数据格式的校验。支持灵活配置的校验级别,可自定义校验规则。校验内容包括字段数目,字符长度、字段类型、取值范围等。校验在数据进入数据总线前完成,校验不合法有明确的提示。
(2)数据拆分
数据拆分可以根据业务特性将大规模原始数据拆分为若干类数据,业务各取所需,既提高了业务计算的效率,也减少了对底层资源的占用。
(3)数据过滤
数据过滤是对接入的数据进行质量评测,如发现内容为空的数据、重复的数据,则进行过滤。
(4)数据去重
数据去重是对接入的数据进行数据监测比对,对于重复的数据进行去重操作,仅保留一条数据。
5.2.4 数据持久化
数据持久化模块提供结构化数据持久化、非结构化数据持久化、全文持久化、分区计算、持久化策略控制、合规验证的能力。实现对各类日志数据、事件数据、资产数据等结构化数据以及非结构化数据的持久化功能。
在本次投标方案,根据项目需求,我们将结构化流量日志类数据持久化到Hive数据库中,以支持数据的分析功能;安全事件类型数据、资产数据、基础信息数据持久化到Hive数据库和ES全文数据库,以支持数据的检索和分析功能;将pcap包、样本文件等文件型数据持久化到对象存储引擎。
数据持久化模块支持实现数据加载容错和加载负载均衡(如图所示),该方案可以做到当单台加载机出现故障时,加载流量自动切换到其他加载机。同时支持对故障节点的快速探测,自动识别异常节点,对异常节点自动下线,并对恢复后的节点自动上线。对加载服务的故障自动检测和切换,能够对用户透明。支持集群部署模式下的负载均衡,并支持动态扩容,在此实现了轮询、随机等复杂均衡方式,满足加载容错和复杂均衡的需求。
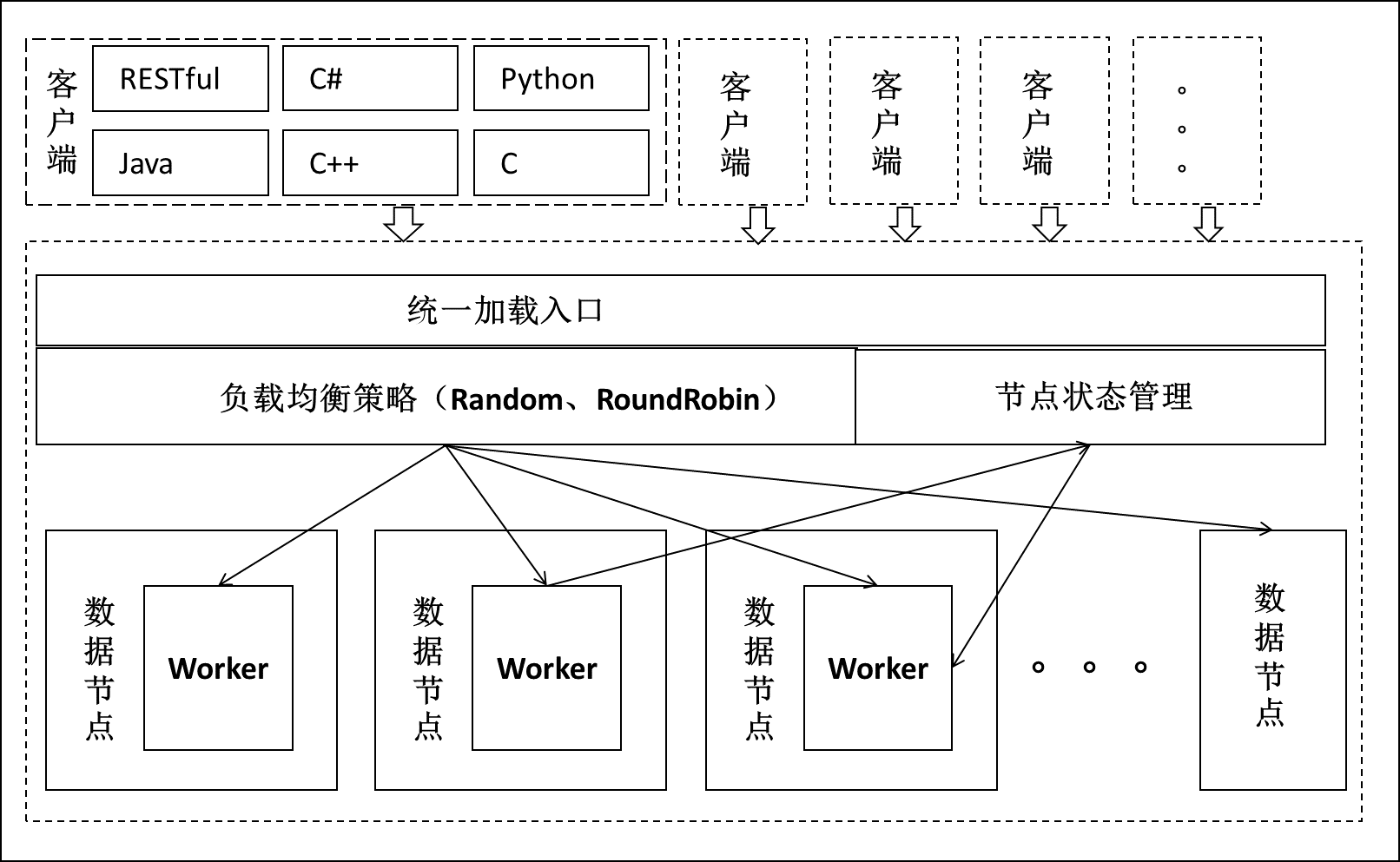
图 5统一数据加载示意图
集群内部机器故障时,加载容错和负载均衡的功能实现对业务无感。负载均衡支持多业务混合使用,不同业务对应不同的域名/IP,支持基于业务的流量控制。
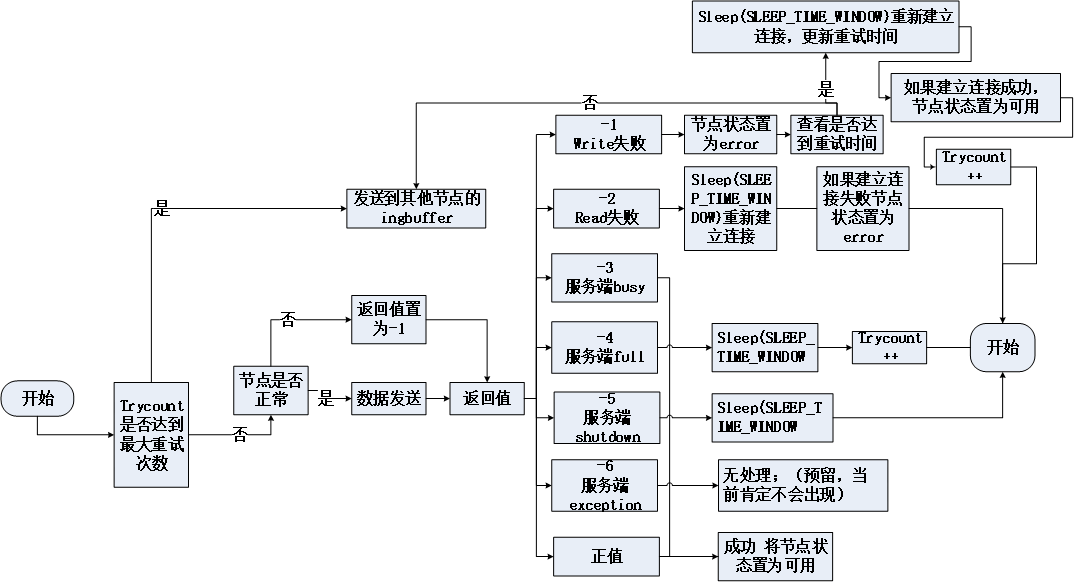
图 6客户端模式的负载均衡和容错原理示意图
主要的关键技术说明如下:
支持对结构化数据、非结构化数据和全文数据的加载,支持对结构化的字符型、数值型、布尔型、时间型以及二进制等数据类型的数据加载,支持对pcap包、样本文件等非结构化数据的加载,支持全文数据的分词、索引和加载管理。
支持按照业务入库时间进行数据的自动分区管理功能,将不同的数据存储在不同的分区中,实现数据的高效管理。分区的规则支持按天、按月进行,分区对用户透明,用户在检索的时候无需感知分区分布。因为采用分布式并发框架进行数据的加载,就需要实现分区自动计算,同时加入文件句柄控制等模块,在充分考虑了短时间内超多分区数据进入的情况,采用了worker发起,master执行的分区自动计算方式,实现了分区的自动离线计算功能。
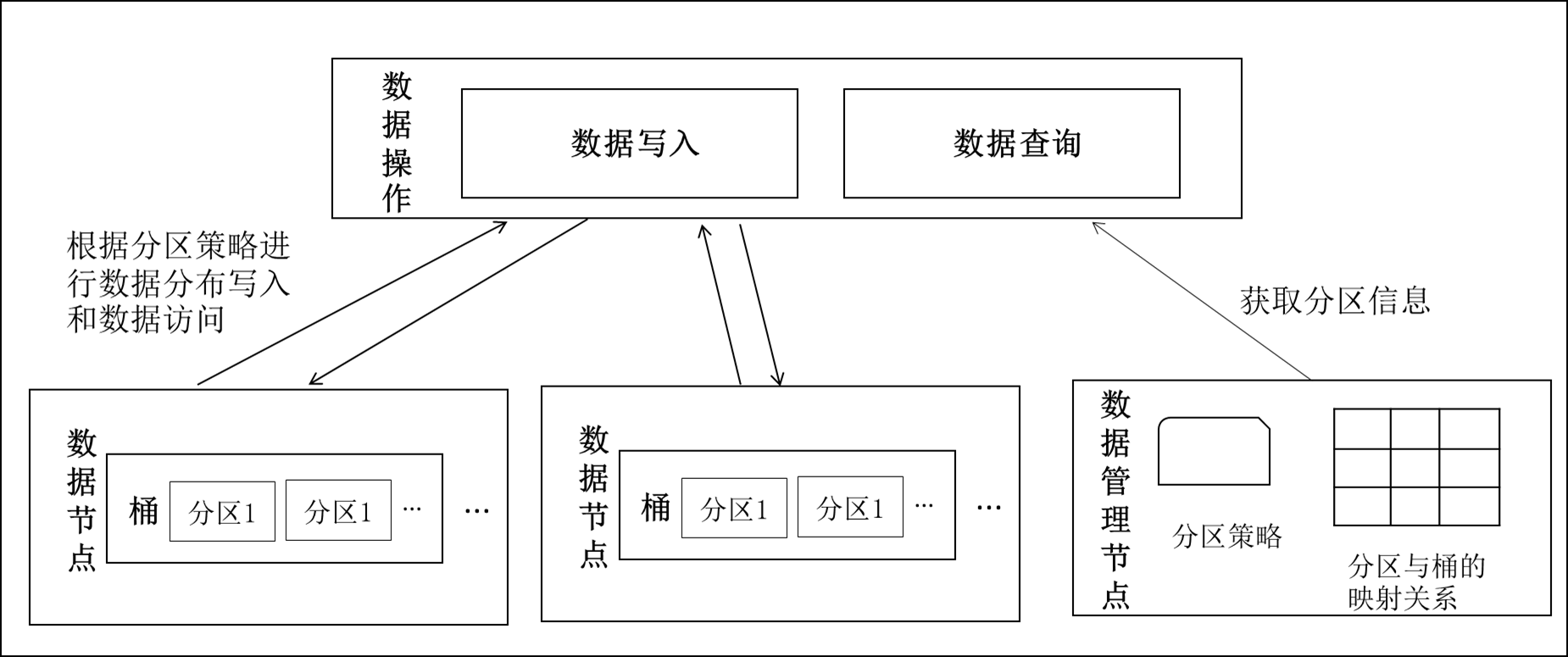
图 7分区组织管理
5.2.5 数据归一化
数据归一化实现的业务流程是,针对来自公司总部大厦、公司分部大厦数据,按照数据的业务含义,将不同来源、相同业务含义的数据,按照数据规范,对数据进行数据聚合和再组织。对底层不同来源数据存在的差异和不统一,进行屏蔽,方便上层业务的分析和使用。
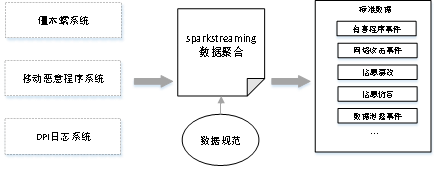
图 8数据归一化示意图
数据来源众多,需要基于不同的来源的数据按照统一的分类体系进行归一化,其中,聚合分类通过实时spark streaming程序完成。
针对僵木蠕系统、移动恶意程序系统、DPI日志系统等产生的安全事件数据,按照业务含义进行数据聚合,将不同来源、相同业务含义的数据,融合到统一的数据规范中。
5.2.6 数据质量核查

图 9数据合法性校验
数据质量核查在对字段数目、字段类型、取值范围等类型进行加载的时候,加载服务将根据设计的逻辑进行数据合法性校验,在发生错误时给出明确的数据不合法提示。数据质量核查提供结构化数据的数据字段内容标准管理功能,支持用户自定义扩展字段内容标准,可通过正则表达式、UDF等方式进行数据字段内容标准的扩展。支持统计字段条目数、字段填充率、字段错误率等信息的核查,对数据汇入的各个环节进行实时监控,及时发现数据丢失、数据断流等严重问题;对数据接入源头实时检查,拦截清洗脏数据,减少后续资源消耗,同时,定时综合检查,指导生产改进。
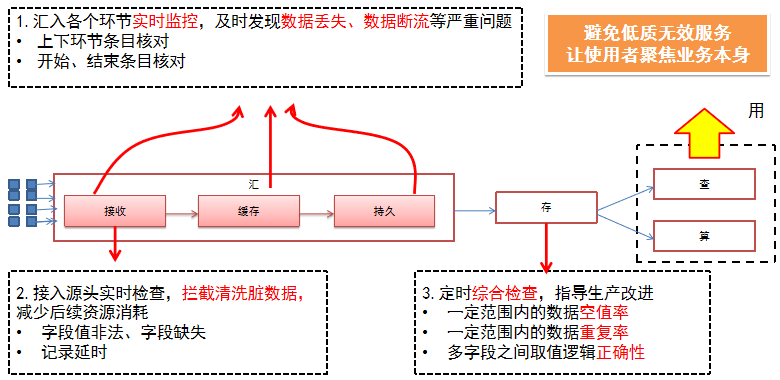
图 10数据质量核查流程图
下图所示为质量稽核任务管理界面截图:
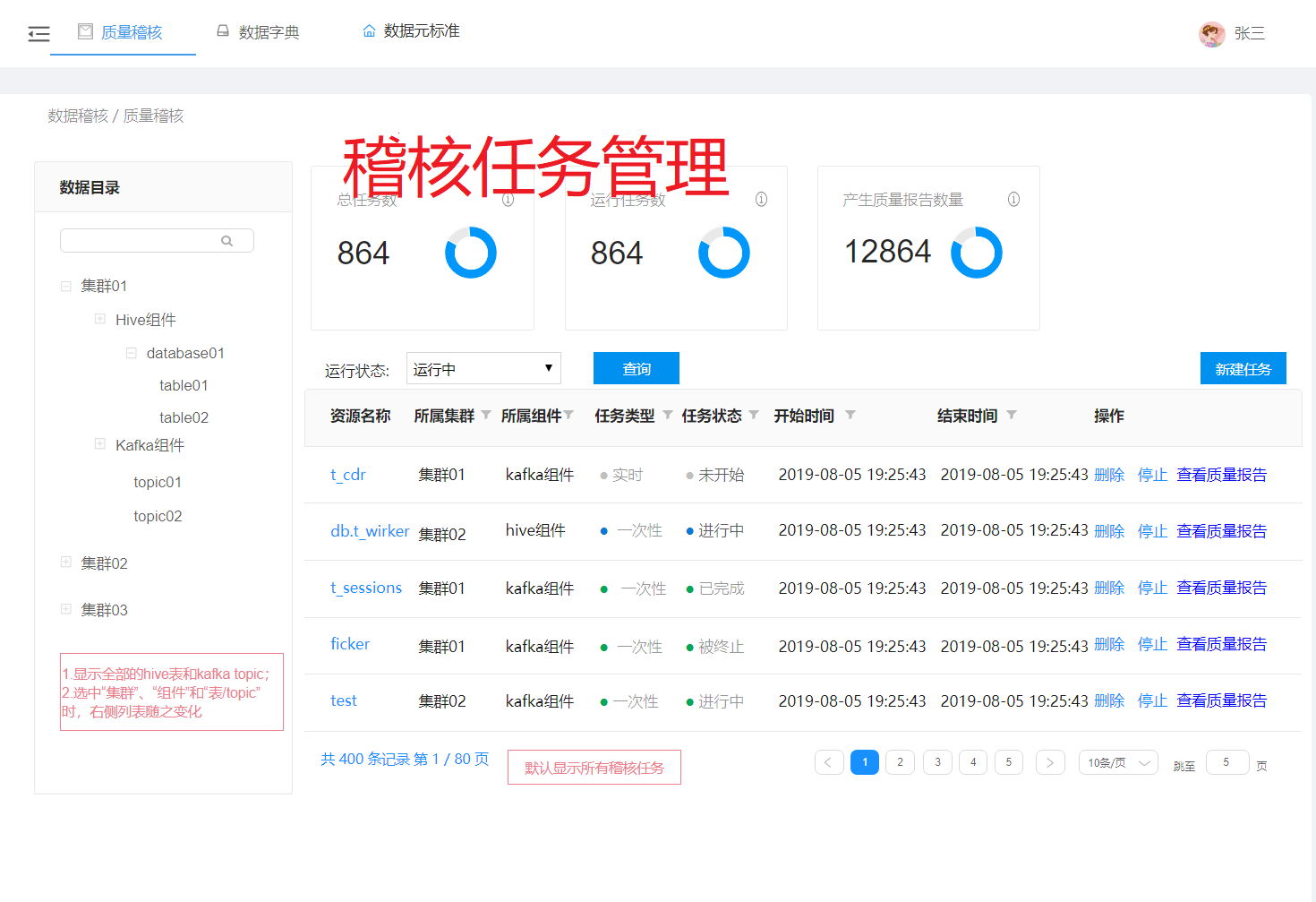
图 11质量稽核任务管理
稽核任务管理模块统计指标有集群的“任务总数”、“运行中的任务数”、“产生的质检报告数量”。“统计信息”随目录树选中项的“所属集群”变化而变化,如果用户在同一集群下的组件间切换时“统计信息”不变,均显示该集群的统计情况。
稽核任务管理模块提供列表的形式展示当前集群所有的质量稽核任务。
任务列表展示数据源名称、所属集群、所属组件、任务类型、任务状态、开始时间、结束时间和操作信息,用户可对任务进行的操作有“停止”、“删除”和“查看质检报告”。
“任务类型”包含“实时”和“一次性”两种类型。
“任务状态”包含“运行中”、“已完成”、“已停止”和“运行失败”四种状态。
“任务列表”与“数据源目录树”联动,选中某集群时列表显示该集群的所有稽核任务,选中某组件时列表显示该组件的所有稽核任务,选中某数据库时列表显示该数据库的所有稽核任务,选中某table/topic时列表显示该table/topic相关的所有稽核任务。
5.3 服务接口
服务接口模块为上层工业互联网态势感知平台提供服务接口,用于对存储至数据平台的数据进行检索、分析,主要包括SQL接口、文件接口、全文检索接口、数据订阅接口、对象检索接口。
5.3.1 SQL接口
该部分提供Java、C等多语言编程接口,提供Shell操作命令接口,提供数据库连接接口,支持SQL检索、实时统计、实时筛选、流与静态关联计算的能力,为上层业务平台提供基础支撑能力。
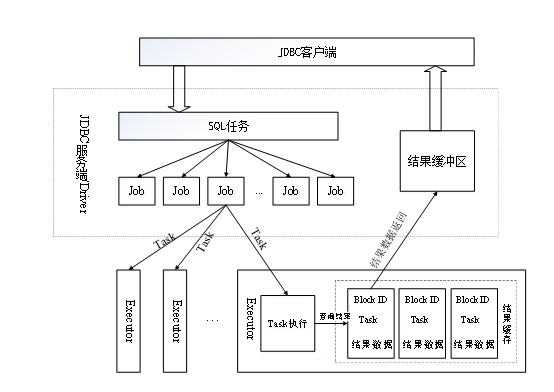
图 12统一检索引擎示意图
元数据服务维护了软件内部库表元数据,并支持注册维护了外部系统中的非结构化库表元数据、全文数据库表元数据和数据总线数据。依托于软件元数据服务对外输出的统一视图,使用SQL完成异构数据源的统一检索与融合分析,通过JDBC、ODBC接口对外服务。使用Spark对hive、es、mysql等引擎的统一检索。
基于该模块实现对日志数据、资产数据、事件数据的SQL检索功能,满足分析业务对于离线结构化数据精确条件检索、模糊条件检索、多表关联检索、求和统计、计数统计、范围检索需求。
SQL语法包括但不限于以下内容:
Ø 标准SQL语法
|
SQL 关键字 |
描述 |
|
WHERE和HAVING |
条件过滤 |
|
ORDER BY |
全局排序 |
|
SORT BY |
分组排序 |
|
GROUP BY |
按列分组 |
|
JOIN |
多表关联 |
|
WITH...AS |
公共表达式 |
|
UNION |
并集 |
|
INTERSECT |
交集 |
|
EXCEPT |
减去 |
Ø 函数
|
内置函数 |
描述 |
|
COUNT |
统计符合条件的记录数 |
|
SUM |
对特定值求和 |
|
MAX |
求最大值 |
|
MIN |
求最小值 |
|
AVG |
求平均值 |
|
LENGTH |
统计长度 |
|
UPPER |
将英文字母转换为大写字母 |
|
LOWER |
将英文字母转为小写字母 |
|
LEVEL |
域名分级函数 |
|
UNIX |
时间戳函数 |
|
DATE_ADD |
日期增加函数 |
|
DATE_SUB |
日期减少函数 |
5.3.2 文件接口
文件接口部分,提供JAVA、C等多语言编程接口,提供Shell操作命令接口,接口包含了全部的文件操作功能,如文件及目录的创建、删除,文件的随机读写,顺序读写,文件大小、创建时间等信息的查看等。支持Pcap文件、还原文件的读写场景,可实现离线数据的的导出和推送。文件接口相关的操作如下所示:
Ø 公共HTTP头定义
|
名称 |
描述 |
|
User-Name |
请求此次服务的用户的名称。 |
|
Password |
请求此次服务的用户的密码。 |
|
Content-Length |
HTTP请求内容长度。 |
|
Content-Type |
HTTP请求内容类型。 |
|
Date |
HTTP 1.1协议中规定的GMT时间,例如:Wed,05 Sep. 2020 23:00:00 GMT |
|
Host |
访问Host值。 |
Ø 公共响应头
|
名称 |
描述 |
|
Content-Length |
HTTP请求内容长度。 |
|
Connection |
标明客户端和服务器之间的链接状态。 |
|
Date |
HTTP 1.1协议中规定的GMT时间,例如:Wed,05 Sep. 2020 23:00:00 GMT |
|
Server |
生成Response的服务器。 |
Ø 关于Service操作
|
API |
描述 |
|
得到该账户下所有Bucket |
|
|
Get User UsageState |
监控某用户资源使用情况 |
|
addUser |
添加用户 |
|
updatePasswd |
更新密码 |
|
deleteUser |
删除用户 |
|
getUser |
获取用户【用户名及密码】 |
Ø 关于Bucket操作
|
API |
描述 |
|
创建Bucket |
|
|
设置Bucket访问权限 |
|
|
设置Bucket中Object的生命周期规则 |
|
|
Put Bucket MaxSize |
设置Bucket资源容量上限。 |
|
Put Bucket MaxObjects |
设置object数量上限。 |
|
获得Bucket访问权限 |
|
|
查看Bucket中Object的生命周期规则 |
|
|
删除Bucket |
|
|
获得Bucket中所有Object的信息 |
|
|
获取Bucket信息 |
Ø 关于Object操作
|
API |
描述 |
|
上传object |
|
|
获取Object |
|
|
删除Object |
|
|
删除多个Object |
|
|
获得Object的meta信息 |
|
|
在Object尾追加上传数据 |
|
|
上传多个本地的文件到对象存储系统中 |
5.3.3 全文检索接口
全文数据检索接口支持全文数据的存储与检索能力,支持对日志数据等的交互式检索功能,提供SQL查询、访问并行控制、数据分词索引、数据管理、更新控制的能力。支持多语言API,提供多种查询方式,包括shell查询、Java API查询、JDBC查询、RESTful查询等,支持spark SQL的访问语法,支持实时查询,支撑计算引擎,可以基于SQL的自定义相关排序,提供多种数据检索方式,查询结果支持权重设置、分组统计、相关度排序等功能。
5.3.3.1 数据表管理模块
数据表管理包含表的创建、查看、删除,设置表的生命周期、配额、分片数、副本数、创建人、创建时间。
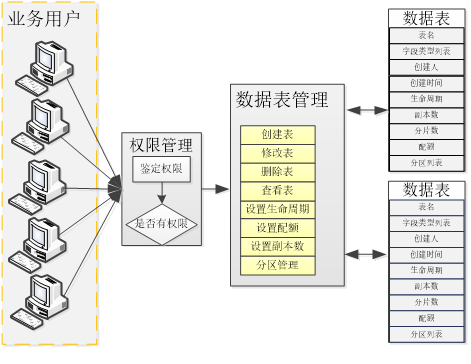
图 13数据表管理模块
Ø 生命周期
生命周期管理模块支持数据生命周期自动管理,可以按落地时间或业务时间自动维持数据的生命周期,实现了数据表时间维度的管理。
Ø 配额管理
配额管理模块支持数据表的总空间管理,当数据表总容量达到设置配额总量时旧的数据会被更新的数据替代,实现了数据表容量维度上的限制。
Ø 分区管理
分区管理模块支持按天、月划分分区,为数据检索时提供分区裁剪,使提高检索目标的精确性,提高检索效率。
Ø 分词索引管理
支持动态分词器管理,支持通过配置的方式实现词条的动态更新。
5.3.3.2 数据检索模块
数据检索功能包括WEB界面查询、shell界面查询、Java API查询、JDBC查询、restful查询。支持短语查询、模糊查询、临近查询、精确查询、通配符匹配、设置权重、形状查询、边界查询、多边形查询、分组统计、相关度排序等。
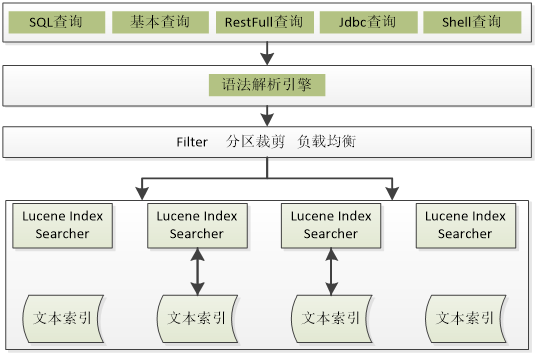
图 14数据检索模块
数据查询服务启动时读取配置信息完成系统初始化,然后在负载均衡器上注册,之后开始等待客户端到来的查询请求;
负载均衡器收到数据查询请求;
负载均衡器按照均衡规则动态绑定一个数据查询服务给请求方;
查询服务解析查询语句,并调用并行检索接口,将请求下发至并行关键字检索服务进行处理。并行关键字检索服务执行检索请求,将结果返回给查询服务,查询服务将查询结果直接返回给客户端。
全文库是一个分布式的存储和检索系统,在存储的时候默认是根据每条记录的_id字段做路由分发的,这意味着服务端是准确知道每个document分布在那个shard上的。
l 全文SQL实现方式
提供全文SQL的语句转换功能,主要是:基于Antlr的类SQL语句解析技术以及SQL查询规划技术。对复杂检索任务的规划执行。
l SparkSQL 运行架构
Spark SQL采用类SQL语法,类似关系型数据库语法,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、DataSource、Schema四部分构成:
Ø Core:负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等。
Ø Catalyst:负责处理整个查询过程,包括解析、绑定、优化等。
Ø DataSouce:负责对数据源的访问和处理。
Ø Schema:主要用于数据类型的定义和映射等。
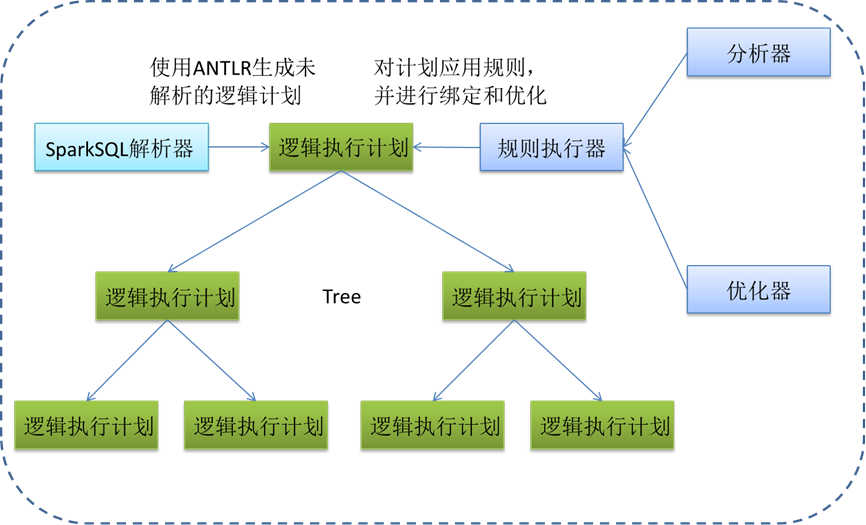
图 15查询逻辑架构
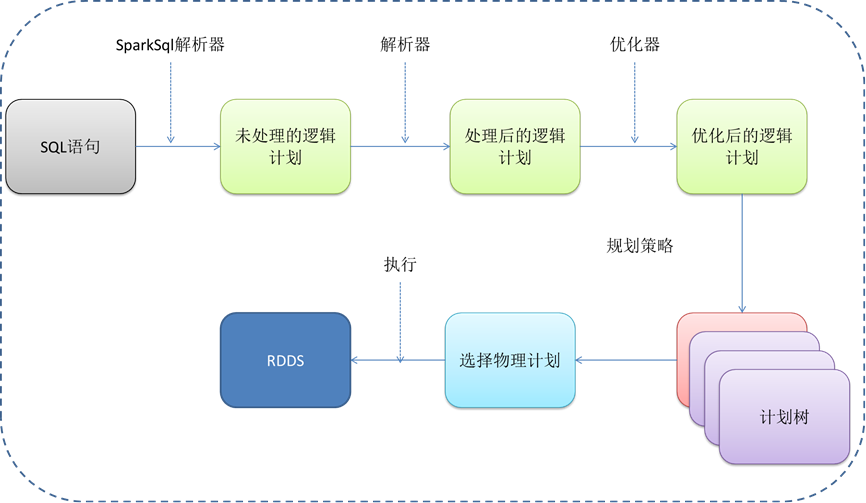
图 16查询逻辑流程图
一般情况下查询可分为两步:首先把数据读入到SparkSQL中,SparkSQL进行数据处理或者算法实现,然后再把处理后的数据输出到相应的输出源中。
SparkSQL支持ES数据源,需要进行数据类型的映射,定义表结构及字段的类型和Scala中的数据类型映射关系,来实现数据表中的字段类型到SparkSQL数据类型的映射关系。
关于数据结构采用的是DataFrame数据结构来组织读入到SparkSQL中,DataFrame数据结构其实与数据库表结构相似,数据是按照行来进行存储,同时还有一个Schema,就相当于数据库的表结构,记录着每一行数据属于哪个字段。
当数据处理完以后,将把数据输出到指定的输出源中,并且以指定的格式进行对应。
l SparkSQL 运行原理
使用SessionCatalog保存元数据信息:
在解析SQL语句之前,会创建SparkSession(2.0之前的版本初始化SQLContext,SparkSession是封装了SparkContext和SQLContext的创建过程)。其中元数据会保存在SessionCatalog中,元数据包括表名,字段名称和字段类型。这样在创建临时表或者视图,会在SessionCatalog中进行注册。
解析SQL,使用ANTLR生成未绑定的逻辑计划:
当调用SparkSession的SQL或者SQLContext的SQL方法时,使用SparkSqlParser进行SQL解析。使用ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
词法分析:Lexical Analysis,负责将token分组成符号类
构建一个分析树或者语法树AST
一个完整的运行过程为:
1、 使用分析器Analyzer绑定逻辑计划:Analyzer使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
2、 使用优化器Optimizer优化逻辑计划:优化器定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行合并和优化
3、 使用SparkPlanner生成物理计划:SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan。
4、 使用QueryExecution执行物理计划:调用SparkPlan的execute方法,生成执行任务,然后返回RDD/DataFrame。
l 查询调度流程
调用SearchQueryThenFetchAsyncAction.start(...)之后,查询即进入了以协调节点为中心的查询调度过程,即两个核心阶段Query Phase、Fetch Phase的执行,具体如下面时序图所示。此外,查询调度还包含两个轻量级阶段Expand Phase、Reponse Phase。
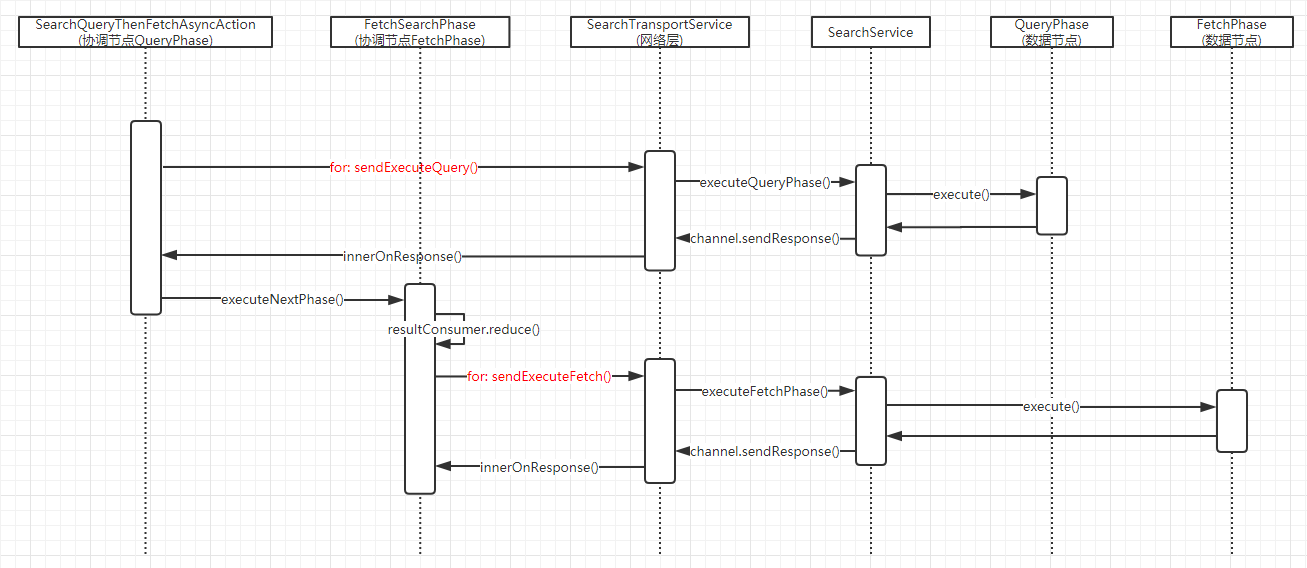
图 17查询调度流程
Ø 协调节点
SearchQueryThenFetchAsyncAction是Query Phase的入口,进入Query Phase后,会立即根据并发度参数进行Query任务的分发,具体由祖父类InitialSearchPhase的run(...)函数进行,通过SearchTransportService的sendExecuteQuery(...)函数,向具体分片发送Query子任务进行异步分布式执行,每个分片在执行完毕Query子任务后,通过节点间通信,回调祖父类InitialSearchPhase的onShardSuccess(...)函数,把查询结果记录在协调节点保存的数组结构results中,并增加计数,当返回结果的分片数等于预期的总分片数时,协调节点会进入当前Phase的结束处理,启动下一个阶段Fetch Phase的执行。只需要一个分片执行成功,即会进行后续Phase处理得到部分结果,当然会在结果中返回实际有多少分片执行成功。
Ø 数据节点
协调节点通过SearchTransportService的sendExecuteQuery(...)函数向目标数据节点发送QUERY_ACTION_NAME类型的查询子任务,通过请求标识QUERY_ACTION_NAME在SearchTransportService中调用对应的处理函数SearchService.executeQueryPhase(...),数据节点通过canCache分支的Query Phase处理,利用Cache优化查询, QueryPhase.execute(...)为数据节点进行Query Phase子任务的核心逻辑,它首先从searchContext中获取查询参数和查询对象query,然后生产处理查询结果的collector,最终调用Lucene的IndexSearcher.search(...)函数进行查询。
5.3.3.3 全文检索数据类型
全文检索数据类型如下所示:
|
数据类型 |
描述 |
实例 |
|
TINYINT |
1字节(8位)有符号整数,从-128到127 |
1 |
|
SMALLINT |
2字节(16位)有符号整数,从-32768到32767 |
12345 |
|
INT |
4字节(32位)有符号整数, |
-1234567 |
|
BIGINT |
8字节(64位)有符号整数, |
12345678910 |
|
FLOAT |
4字节单精度浮点数 |
1.001 |
|
DOUBLE |
8字节双精度浮点数 |
1.000001 |
|
DECIMAL |
任意精度的,有符号的十进制数 |
1.012, 1e+44 |
|
BOOLEAN |
true/false |
TRUE/FALSE |
|
STRING |
字符串 |
'a',”a” |
|
VARCHAR |
可变长度的字符。最大长度个字符。 |
'a', 'a b' |
|
DATE |
日期。格式:'YYYY-MM-DD', 从'0001-01-01’到'9999-12-31' |
'2020-01-01' |
|
TIMESTAMP |
时间戳,表示日期和时间。格式:'YYYY-MM-DD HH:MM:SS.fff',可达到小数点后3位(毫秒级别)精度 |
'2020-01-01 00:00:00' |
|
TEXT |
文本,用于全文检索 |
‘我爱中国’ |
|
IPV4_ADDR |
IPv4类型(4字节), 最大长度为15位,格式为:x.x.x.x,数值范围[0,255], 支持IP类型数据的区间检索、子网检索、系运算符 |
[255.255.255.255] |
|
IPV6_ADDR |
IPv6类型(16字节), 按网络字节序转为32位十六进制,格式为:x:x:x:x:x:x:x:x;不支持通配符查询,支持关系运算符,支持子网检索,区间检索 |
ABCD:EF01:2345:89::EF01:2345:6789 |
5.3.3.4 全文检索语法
全文检索语法包括但不限于以下函数:
|
函数 |
描述 |
|
FULL_TEXT |
全文字段匹配检索 |
|
FULL_TEXT_SUBSTRING |
子串匹配检索 |
|
RANGE |
范围查询 |
|
WildCard |
通配符查询 |
|
Fuzzy |
模糊查询 |
|
Regexp |
正则查询 |
|
Phrase |
短语/临近查询 |
|
Boolean |
组合查询 |
|
Boost |
权重查询 |
5.3.4 数据订阅接口
数据订阅接口,可按照给定的订阅语法,实现数据定向推送功能。融合发布订阅平台和消息队列平台的特点,即支持多个消费者对单个或多个主题分区的订阅模式,又支持单个消费者对单个主题分区的队列消费模式,而且主题分区本地化存储消息,提供消费者对主题分区的仅一次消费、历史消息回溯消费和选择性消费等多种消费方式。
数据订阅接口的基本信息流程实现,消费者可以订阅一到多个主题,拉取消息进行数据处理操作,不同的消费者组成消费者组,同一个主题分区只能被同一个消费者组内的一个消费者订阅。服务代理和消费者采用Zookeeper获取分布式消息交换对象的状态信息,以及跟踪消费消息的偏移量。
复杂订阅构建在数据总线基础之上,借助数据总线提供的分区控制、数据订阅、消费特性控制、数据生产、数据复杂订阅、数据镜像、数据副本的能力,按照给定的订阅语法,实现数据定向推送功能。为实时统计、数据分析等业务场景提供基础支撑能力。支持多个用户按照组授权进行数据的分享交互功能,支持全局多个数据总线之间的数据交互能力。
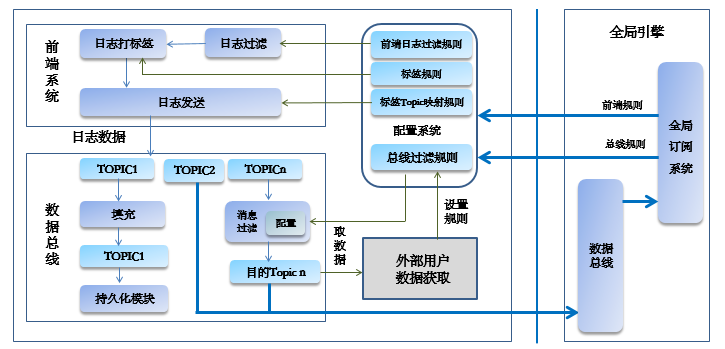
图 18数据复杂订阅
通过复杂订阅的规则管理功能,使用类SQL的规则描述语法,支持对于特定数据的在线实时过滤功能,其中包含区间筛选、等值筛选、前模糊筛选、后模糊筛选、中间模糊筛选以及正则匹配筛选多种复杂筛选数据的模式。
数据订阅的接口操作如下所示:
|
API |
描述 |
|
Connect |
Kafka连接接口 |
|
Consumer |
数据消费接口 |
|
Streams |
支持数据流从输入主题转到输出主题 |
5.3.5 对象检索接口
对象检索接口为态势感知平台提供多源数据的对象检索能力,支持还原文件的读写场景。支持通过Spark作业处理非结构化数据,同时支持提交Spark任务的方式对存储系统中的非结构化数据进行离线的分析处理。支持按对象属性信息快速提取对象,提供对对象数据的随机读、追加写、覆盖写等操作接口。提供多种用户交互方式,能够通过命令行方式直接进行非结构化数据的上传、下载、删除和文件信息查看,同时提供了类S3的RESTful方式的访问接口和API方式的访问接口。通过本模块支持多对象数据种类的访问和控制。
l SHELL命令设计
通过开发基于X86服务器上系统支持的SHELL版本。该接口完成了直接对文件元数据信息的查看、文件删除、文件件上传和文件下载功能。
l 类S3的HTTP接口设计
设计实现了类S3方式的访问接口,支持HTTP1.1标准,实现了外部程序唯一访问入口的功能。支持了数据访问存储、用户租户管理、数据桶管理、权限管理和集群管理的全部功能。
l 多语言API接口设计
实现API方式的访问接口,实现了对支持了Java(支持1.7版本以上)、C/C++(支持Linux3.2以上版本)和C#(支持.NET3.0以上版本)。所有语言的接口都实现了对数据访问存储、用户租户管理、数据桶管理、权限管理和集群管理的全部功能。
l Spark引擎的支持
提供了HDFS标准的Spark数据访问驱动包,能够很好的对接Spark引擎的计算任务,同时集群内部支持Spark引擎的部署,可以直接通过部署的Spark客户端提交Spark计算任务对数据进行离线分析。
6 公共卫生现场层方案设计
6.1 公共卫生通行方案设计
根据业主的需求进行分析,门禁系统方案设计如下
Ø 在主要出入口安装门禁系统,所有人员出入验证身份,加强内部安全管理。
Ø 主要出入口根据管理要求采用刷卡或“卡+指纹”的识别方式;
Ø 门禁系统采用我公司的双门门禁控制器或单门门禁控制器,采用TCP/IP的通讯方式,可直接接入客户内部网络
Ø 系统所有数据保存在一个数据库中,数据库服务器设置在机房内统一管理,同时根据实际情况设置门禁监控中心,可实时显示各个持卡人的照片,方便保安管理;
Ø 整个系统采用“集中管理、分散控制”的方式,各个操作员由系统管理员授权,操作员可实现多级管理。
6.1.1 网络架构
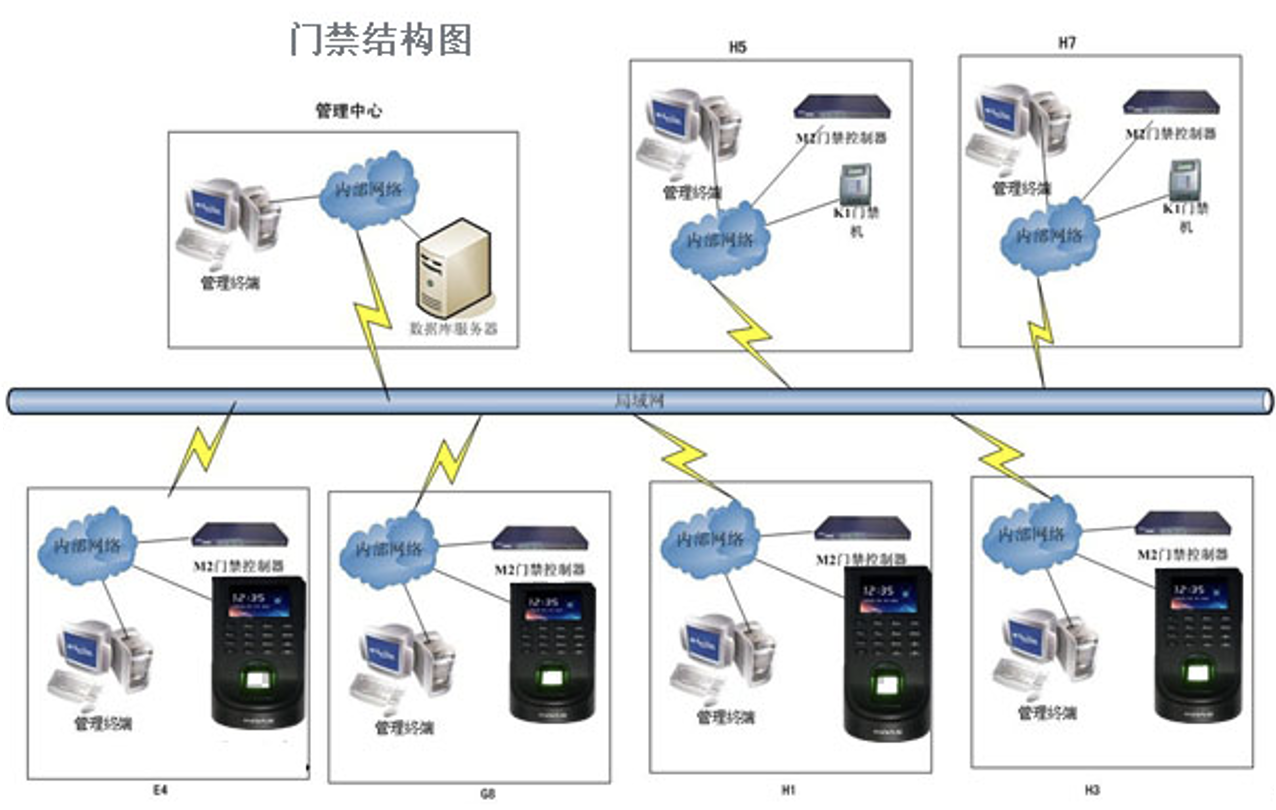
图 19门禁系统架构
6.1.2 系统概述
智能门禁系统基于现代电子与信息技术,在建筑物内外的出入口安装自动识别系统,通过对人或物的进出实施放行、拒绝、记录等操作的智能化管理系统。
门禁管理子系统通过码读卡器和人脸识别仪辨识,利用门禁控制器采集的数据实现数字化管理,其目的是为了有效的控制人员的出入,规范内部人力资源管理,提高重要部门、场所的安全防范能力,并且记录所有出入的详细情况,来实现出入口的方便、安全管理,包含发卡、出入授权、实时监控、出入查询及打印报表等,从而有效地解决传统人工查验证件放行、门锁使用频繁、无法记录信息等不足点。
本项目门禁系统选用知名品牌产品,并接入业主现有门禁管理系统。
6.1.3 系统功能
6.1.3.1 门禁点位设置原则
在办公楼主出入口设置单向门禁管理,即进门刷卡、出门按钮的方式。
在敏感区域如重要机房、研发中心、测试中心等出入口可采用双向刷卡方式与生物识别复合式管理。
在访客进出的通道增设二维码读卡设备,方便线上预约管理。
6.1.3.2 门禁开门时段
周计划配置
门禁周计划是指按一周七天,一天最多4个时段来设置门通道的开门时间段,平台设置门禁周计划后会下发至所有的门禁控制器。人员卡号可通过平台来关联门通道的某个周计划。
如:周计划一:周一至周五“08:00-20:00”,周六至周日“09:00-18:00”
周计划二:周一至周日“00:00-23:59”
则可按实际需求如分配普通员工周计划一,管理员分配周计划二;
系统支持128个门禁周计划设置。
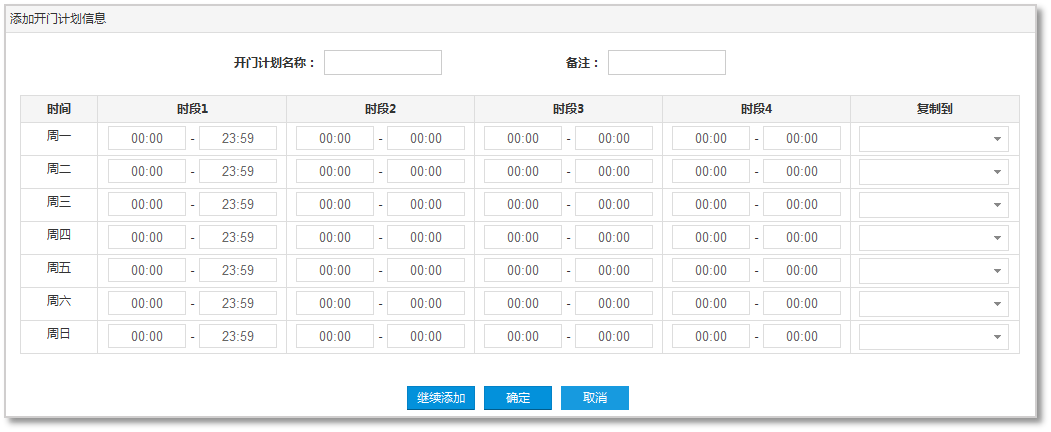
图 20门禁周计划配置页面
常开常闭时段配置
可对门禁点及门组进行常开常闭时间段设置。
6.1.3.3 门禁授权管理
系统采用集中统一发卡、分散授权模式。由发卡中心统一制发个人门禁卡和管理卡,再由门禁系统独立授予门禁卡在本系统的权限。系统可对每张卡片进行分级别、分区域、分时段管理持卡人可进出授权的活动区域。
系统可针对不同的受控人员,设置不同的区域活动权限,将人员的活动范围限制在与权限相对应的区域内;对人员出入情况进行实时记录管理。实现对指定区域分级、分时段的通行权限管理,限制外来人员随意进入受控区域,并根据管理人员的职位或工作性质确定其通行级别和允许通行的时段,有效防止内盗外盗。
系统充分考虑安全性,可设置一定数量的操作员并设置不同的密码,根据各受控区域的不同分配操作员的权限。
门禁授权指对系统已有的人员进行门禁通行授权操作。
系统支持多种门禁授权方式,可按部门、人员及门禁点、门组进行两两组合授权,方法多样,配置方便,支持单个、批量授权。
6.1.3.4 门禁电子地图
门禁子系统以图形的形式显示门禁的状态,比如当前门是开门还是关门状态,或者是门长时间打开而产生的报警状态。此时管理人员可以透过这种直观的图示来监视当前各门的状态,或者对长时间没有关闭而产生的报警门进行现场察看。同时拥有权限的管理人员,在电子地图上可对各门点进行直接地开/闭控制。
n 出入记录查询
系统可实时显示、记录所有事件数据;读卡器读卡数据实时传送给管理平台,可在管理中心客户端立即显示持卡人(姓名、照片等)、事件时间、门点地址、事件类型(进门刷卡记录、出门刷卡记录、按钮开门、无效卡读卡、开门超时、强行开门)等如实记录且记录不可更改。报警事件发生时,计算机屏幕上会弹出醒目的报警提示框。系统可储存所有的进出记录、状态记录,可按不同的查询条件查询,并生成相应的报表。
n 刷卡加密码开门
在重要房间的读卡器(需采用带键盘的读卡器)可设置为刷卡加密码方式,确保内部安全,禁止无关人员随意出入,以提高整个受控区域的安全及管理级别。
n 逻辑开门(双重卡)
某些重要管理通道需同一个门二人同时刷卡才能打开电控门锁。例如金库等,只有两人同时读卡才能开门。
n 胁迫码
防胁迫密码输入功能(需采用带键盘式读卡器)。当管理人员被劫持入门时,可读卡后输入约定胁迫码进门,在入侵者不知情的情况下,中心将能及时接收此胁迫信息并启动应急处理机制,确实保障该人员及受控区域的安全。
n 防尾随
持卡人必须关上刚进入的门才能打开下一个门。本功能是防止持卡人尾随别人进入。在某些特定场合,持卡者从某个门刷卡进来就必须从另一个门刷卡出去,刷卡记录必须一进一出严格对应。该功能可为落实具体某人何时处于某个区域提供有效证据,同时有效地防止尾随。
n 反潜回
持卡人必须依照预先设定好的路线进出,否则下一通道刷卡无效。本功能与防尾随实现的功能类似,只是方式不同。配合双向读卡门点设计,系统可将某些门禁点设置为反潜回,限定能在该区域进、出的人员必须按照“进门→出门→进门→出门”的循环方式进出,否则该持卡人会被锁定在该区域以内或以外。
n 双门互锁
许多重要区域,通行需经过两道门,要求两道门予以互锁,以方便有效地控制尾随或者秩序进入。可以有效地控制入侵的难度和速度,为保安人员处理突发事件赢得时间。互锁的双门可实现相互制约,提高系统安全性。当第一道门以合法方式被打开后,若此门没关上,则第二道门不会被打开;只有当第一道门关闭之后,第二道门才能够被打开。同理,如果第二道门没有关好前,第一道也不予以刷卡打开。
n 强制关门
如管理员发现某个入侵者在某个区域活动,管理员可以通过软件,强行关闭该区域的所有门,使得入侵者无法通过偷来的卡刷卡或者按开门按钮来逃离该区域,通知保安人员赶到该区域予以拦截。
n 异常报警
该系统具有图形化电子地图,可实时反应门的开关状态。在异常情况下可以实现系统报警或报警器报警,如非法侵入、超时未关等。
n 图像比对
系统可以在刷卡时自动弹出持卡人的照片信息,供管理员进行比对。
6.1.4 系统设计
门禁管理系统采用网络架构方式,各门禁控制器通过网络与中心管理服务器联接。
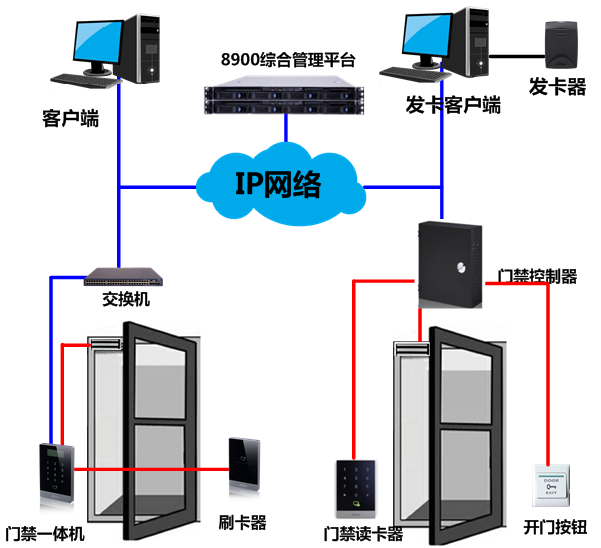
图 23门禁周计划配置页面
前端读卡器或生物设备通过门禁控制器与中心联接,门禁控制器应可以接入多种标准协议的读卡器、人脸识别仪、二维码识别仪。
门锁的选择与实体门密切配合,做到美观、可靠。
6.1.5 感应介质
(1)智能CPU卡;
(2)金融级的活体防伪的人脸、指纹等生物识凭证
6.2 公共卫生消杀方案设计
为了更好的应对疫情防控,减少在封闭聚集场合出现疫情的风险,本次项目需增加重点区域/会议室环境消杀监测模块,保证每天定点定时进行消杀措施,保证每次消杀过程有记录,设备使用有记录,因此本模块系统应支持针对会议室消杀措施的相应设备管理,以及使用情况的实时查询,历史使用情况分析等。
模块可通过权限对不同用户提供不同等级功能。管理人员可通过此模块对消杀路线、方式、时间等进行设置。其他人员可通过此模块进行重点区域/会议室消杀状态的查看,以便进行厦内活动和会议预定等。
具体范围为:第2层2间会议室(多功能厅、贵宾室)、第5层12间会议室,第9层3间会议室使用机器人消杀方案对会议室、楼道间进行消毒作业。
本企业消毒机器人拥有自主导航技术,能识别环境内物品,自主避障;配备消毒管理软件,自动根据空间面积计算消毒时间,并围绕消毒目标进行360°无死角消毒。该款机器人采用超声雾化方式,最大喷射量直径可达6米,消毒液能够以不规则布朗运动弥散到空间的各个角落,进行病毒杀灭。平板电脑、手机均可操控,支持定时喷雾、即刻喷雾两种方式,具有障碍物自动检测、语音提示等多种功能。机器人运用激光雷达技术、视觉传感技术,以实现机器人在自动运行当中的智能避障,自动回充,360度精确消杀,适用于多场景等功能。机器人充满电可连续运行五小时,15分钟可消杀1500平方。
机场、医院、商场等人流密集区域对消毒力度有着较高要求,而传统消毒方式可能出现因操作不到位而导致消毒效果不佳的情况。相比之下,智能消毒机器人无论是在消毒效果、消毒效率上,还是安全性上,都具有无可比拟的优势,消杀率高达99.9 %,这款机器人还拥有自动生成工作报表以及查看区域消毒情况的功能,方便工作人员进行消杀工作的记录和汇总,一系列人性化的功能设置,也让科技闪耀着人文关怀的光芒。
7 系统非功能性特点
平台搭建是按照基于开放式操作系统进行设计,采用B/S架构,整个系统具有稳定性、开放性、易使用性和易开发性等特点。
7.1 程序设计安全性
程序设计的安全性,针对现在大多系统的分布式结构,因为同时要面向不同地理位置,不同网络地址,不同级别,不同权限的用户提供服务,可能产生潜在的安全隐患。系统设计必须避免安全漏洞,主要常见安全漏洞分类:
1、 输入验证漏洞:嵌入到查询字符串、表单字段、恶意字符串的攻击。这些攻击包括命令执行、跨站点脚本注入和缓冲区溢出攻击;
2、 身份验证漏洞:标识欺骗、密码破解、特权提升和未经授权的访问;
3、 授权漏洞:非法用户访问保密数据或受限数据、篡改数据以及执行未经授权的操作;
4、 敏感数据保护漏洞:泄露保密信息以及篡改数据;
5、 日志记录漏洞:不能发现入侵迹象、不能验证用户操作,以及在诊断问题时出现困难。
7.2 数据采集指标
重点用能单位现场能耗数据采样周期不高于10分钟,可根据实际情况要求缩短采样周期。系统具备较好的扩展性,在增加新的计算和存储资源后,系统服务能力能够线性提升,支持多个城市项目和多个区域项目能管中心的数据逐级接入和处理,并可提供同样的服务性能。
1、 性能指标
Ø 同时在线人数支持不少于100人;
Ø 并发请求数不少于200;
Ø CPU平均使用率低于60%;
2、 系统响应指标
|
功能名称 |
性能要求 |
|
数据提取 |
支持按照一定格式,自动提取信息,并进行数据完整性、合法性检查;处理时间<2秒; |
|
数据保存 |
向数据库中更新的速度<1秒; |
|
数据信息编辑 |
能够对于关键字以外的字段进行修改,并检查数据的完整性、数值的合理性,有相似性和重复性检查;响应时间不大于2秒; |
|
查询检索 |
简单查询响应速度<2秒;复杂和组合查询响应速度<5秒;能够对相关文件进行检索、模糊查询;查询结果可按照一定原则进行排序、筛选、保存;查询结果以为图形或图表形式展示,要求输出到通用的办公处理软件中。 |
|
制表 |
固定制表处理时间不大于2秒; |
|
备份恢复 |
应用系统和数据库系统等的备份、恢复定期自动进行,也可以人工进行;提供数据库和表两级备份恢复,处理时间不大于60分钟; |
|
权限管理 |
根据用户类别,划分角色和权限,处理时间不大于2秒钟; |
|
系统日志 |
系统运行日志应记录对系统数据的修改、访问日志;可以定期清理;数据库应当有日志文件,以做备份恢复,处理时间不大于1分钟; |
|
接口管理 |
业务系统之间的数据交换时间不大于1分钟。 |
7.3 界面交互
系统必须支持B/S架构,支持市场上主流浏览器,包括但不限于:IE9以上、Google Chrome, 360, Firefox等 。并支持多版本页面的人工手动切换。
支持AJAX技术,并能满足独立更新页面各个部分。
支持终端适配,能根据不同的访问设备和信息浏览手段,自动进行页面格式转换,包括计算机终端、大屏幕等。最低分辨率可为1366×768,支持4:,3和16:9两,种屏幕比例;常规分辨率为1366×768和1920×1080。
系统软件中的字体、页眉、页脚、色彩方案、图标和logo符合天正公司统一视觉。
支持通过Java Script、CSS来控制页面的样式和布局。
具备修改和删除业务规则类的操作的信息提示,例如当用户修改或删除业务规则或业务规则参数时,系统必须清晰地告知修改或删除造成的影响,以及规避措施,并且默认的操作是“取消”,以避免用户误操作执行了修改或删除。
对于操作员无权限使用的菜单功能,应用系统可不显示该菜单或将其设置为不可用状态。
7.4 程序部署及操作系统安全性
就程序部署及操作系统安全性而言,我方会采取一定的措施保证其安全性。例如:安装全部的安全补丁,关闭所有不需要的系统服务,定期检查系统日志,建立专门操作系统用户来运行应用服务器等。
7.5 数据库安全性
为保证数据安全性,我方采用一定的措施,例如:限制数据库监听地址,制定数据库备份等。
7.6 软件性能
软件性能关注的不是软件是否能够完成特定的功能,而是在完成该功能时展示出来的及时性。系统软件具备以下性能:
(1)用户权限管理系统能够采用模块化系统,便于管理和维护;
(2)用户权限管理系统可以实现多用户同时操作,但不支持管理者与用户同时操作;避免多个用户或管理人员之间因同时操作而产生的错误与冲突;
(3)系统的可维护性和实用性强;保证该系统能最大程度满足用户的需求,出现问题时便于维护和修改。
7.7 系统可靠性
我方所有提供的软硬件都有很多成功案例,系统并应具备可扩展性;
系统中的某一软件功能出错不会导致其它功能出错;
具备冷备、温备、热备等多种灾备技术,包括群集等多种技术机制的高可用性双机冗余,能够防止单点故障的发生;
支持脱机与联机在线备份、恢复功能;
系统中某一设备硬件出错不应导致整个系统出错;
日常硬件维护不应影响正常的系统运行;
支持SAN、NAS等存储,具备存储IO设计与优化技术,支持数据压缩存储功能;
系统能够恢复直至系统发生故障前的最后一次成功完成的事务处理的所有数据;
我方会提供一系列监控、诊断和转换工具以管理数据环境和操作系统;
我方提供优化系统备份、恢复和预防性维护程序,这些程序可通过批处理文件执行以保证最大程度地避免人工介入;
系统具备完善的预警体系,便于用户对异常、突发情况做出快速反应。用户可根据实际需要,定义需要预警的信息及预警条件,同时能够集中查看预警信息;
系统能够自动生成完整的系统工作日志和详细的用户访问记录。


